


Mocking a whole API is realistically very valuable, especially in agile projects, where you work closely with the client, or in headless projects, where a REST or GraphQL API is the main communication interface between the frontend and the backend. Great API mocking can make testing easier and reveal UI and UX problems early in a project. Because we weren’t happy with current services and libraries, we’ve built a new service to fulfil our needs. You can check it out over here—it’s called FakeQL.
In this post, I will explain what good API mocking should be able to do, why API mocking is important and how client projects can take advantage of this new tooling. The goal is to create better products, make clients happier and reduce project costs.
Why Mocking Data and APIs Is Important
Mocking data and APIs in a realistic way is a surprisingly hard task. You'd think for such a basic need and valuable part, there would be dozens of tools and web services available, hundreds of articles written and decades of experience to come up with best practices. But the reality is, sadly, quite bleak. While you can find many HTTP stubbing services meant to test specific requests, actual API mocking is a rarity.
At Unic we have a long history of mocking data and, recently, mainly driven by the transition to more and more API driven, headless projects, API mocking finally evolved into something that is truly useful for modern projects.
Why Mock an API?
There are many reasons why you should mock an API. We’ll have a look at most of them later. Let’s get into the most important ones first.
The Backend isn’t ready
The most common reason to mock an API is that there’s simply no real one available yet. This happens very often, as frontend and backend teams work in parallel and things need to be implemented in the frontend before the backend can deliver anything. In an ideal world, this would never happen. But real projects are never developed in an ideal world where deadlines don’t exists. So this is the norm, not the exception.
The Content isn’t ready
Even if a backend exists, without content in the database—ideally a lot of content—it’s not of much use. If the project is a relaunch project, chances are that we’ll be able to import data from the old system, solving this problem. In many cases, though, all we can do is manually add content to the CMS or database. This is very time-consuming, because for many things, for example to test paginations, it’s not enough to just add one or two entries. And we really can’t expect a client to pay for all those hours spent adding fake content. And besides that, it wouldn’t be a very satisfying job for the developers, anyway.
Faster iterations
Even if the backend is implemented and content is available, there are still some very good reasons to mock an API. Being able to iterate faster on features during development is one of them—a very valuable one. Changing a backend implementation can be very costly and time-consuming. But as projects evolve through months and months of development, change requests naturally occur and are an important part of creating a great product.
You can plan a project as well as you want, but you will never have the optimal solution from the start. That’s just not realistic. So being able to prevent costly and complex backend implementations for as long as possible is crucial. And you can achieve that by mocking an API, promoting a culture of evolving a product much easier, faster and in an environment that suits the client. By mocking an API, you’re able to tinker on an implementation directly with the client in real time. Clients often need a real prototype, where they can interact directly, to understand the pros and cons of a specific proposal. This makes this kind of workflow hugely valuable if you want to create the best product possible without cost explosions.
To illustrate this further, this is an example of how a simplified real world project plan could look like:

As you can see, the backend and frontend streams overlap for the majority of the project duration. And the content stream, often a client task, comes very late in the development of the product. This makes a lot of sense, as you need most of the implementation ready before the client can add content. And as you really don’t want the client to redo his work if a change request forces you to modify the structure of the data model, you want to give him a finished product for that.
On the frontend stream, normally after the initial setup phase, you probably need access to backend APIs quite early on, often before they’re even ready. Both of the described issues are illustrated with red bars on the image above. And mocking an API from as early on as possible—what we call Frontend First Development—can prevent both.
The Utopia of Mocking
So we’ve established that API mocking is really useful. But what are the general requirements for a perfect solution? Let’s ignore all possible limits and dream up requirements for a perfect solution. Later, let’s compare how close we’ve come and what’s still to do.
Indistinguable from the real thing
This is the most vital requirement. The mocked API should be as close as possible to the actual implementation. But if you look at the problem a little bit closer, you realise that the mocked API could and should actually be better than the real thing. Why?
Highlighting UX and network edge cases
More often than not, real content and real backend implementations can hide possible problems from you. Good API mocking should point out possible UX issues. For example by having very variable content and by containing the longest words that you would reasonably expect to ever be added by the content team. And the mocked API should be able to simulate network edge cases, such as when you have extremely high traffic slowing down your servers. Or even crashing them.
In summary, a good API mocking service should be better than the real thing. Not only in how easy and fast it allows you to change things, but also in how it can point out possible issues that could break on the real thing—long after you’ve shipped the final product.
Our Journey at Unic
At Unic we’ve identified very early that data mocking and later API mocking is very important. Here’s an overview of our journey:
2012: Static JSON files
2014: JavaScript enhanced JSON files
2016: Localhost JSON server
2018: Extended localhost JSON servers with Blowson
2019: Mocked API services with FakeQL
We've started with local JSON files in our frontend prototypes. But soon we realised that this isn’t enough for most projects. So, soon we switched our prototyping framework Estático to work with JavaScript enhanced JSON-like structures. We then used that data to statically render our pages and modules. Having data in only templates, we still couldn’t really mock APIs this way. We started to serve data with simple server scripts inside our prototypes.

The Development of Blowson and FakeQL
Finally, in 2018, I realised that with the move to headless content management systems and more and more complicated projects like Progressive Web Apps and Single-Page Applications, we needed better tooling. I started to work on Blowson and later on FakeQL. Blowson is an open source library that intelligently „blows up“ JSON data by detecting its rules and FakeQL is a service to easily deploy extended data as a fully functional GraphQL or REST endpoint in just seconds.
Features of Great API Mocking
Building a great API mocking solution, I found out soon, isn’t as straight forward as I originally thought. Just by looking at the feature set it should have, this became quite clear:
Generate lots of realistic data easily
Allow to overwrite automatically generated data
Deploy effortlessly for happy developers
Have realistic behaviour—like a real API
Enable fast iterations, to promote tinkering around
Be as predictable as possible, to allow automated testing
Simulate flexible data structures
Simulate UI, UX, and API edge cases
Follow privacy guidelines needed in many enterprise projects
Let’s have a closer look at each feature.
Why realistic data?
Realistic data is an absolute must. But there’s more to realistic data than you would guess at first. The experience we’ve gathered from uncountable client projects has taught us many valuable lessons on what works and what doesn’t, what reveals UX issues and what hides them.
Lorem ipsum is a problem
Many mocking tools already fail here. While „Lorem ipsum“ was especially created to work as placeholder text, it doesn’t do its job well in the context of web design. Initially, the main mistake many developers make is to copy the same parts of Lorem ipsum or even just copy and paste the same sentences to the same fields.
Scripts automatically generating Lorem ipsum texts can prevent this by randomizing the chosen parts. The much bigger problem with Lorem ipsum is that it’s not very well suited to test edge cases. Especially in languages like German or French which have long words. Additionally, every sentence ends with a dot, has no quotes and no hyphenated words. Issues that can occur by breaking words at the wrong place are completely undetectable as we have no experience with the „language“ itself. By faking a real language, we see immediately if a word break happens at the right place.
As an example, this is a naive use of Lorem ipsum. Thankfully something we’ve left behind a long time ago. You will easily spot all the hidden issues with it when compared side-to-side with actual content.



As you can see, would we have built the layout with floats, we would already have a broken page. And have in mind, this is with curated content. You don’t always have that luxury with clients. Real content can be even much more diverse than this.
Minimize surprises with realistic content
Only realistic content can point out possible issues with styles and layouts. Approaches like Lorem ipsum or libraries like Faker.js make your life easier at first, but can hide issues from you. For a long time this meant that we had to write real content by hand or copy it from the client’s old website. While copying existing content isn’t needed anymore with tools like Blowson, it still makes sense to have a few self-curated entries to make sure you really catch all edge cases before deploying to the live system.
Correctly handle empty data
What many miss when creating test data are empty entries and non-required fields. A real schema, and with that, real data, often has non-required fields or allows arrays to be empty. If you write sample data by hand, it’s very easy to forget to add entries like that. This can lead to various problems like unstyled or missing „no entries found“ messages in list views or layout bugs because some part is not there.
Let’s say you’re faking a blog API with users, posts and comments. It’s to be expected that not all posts have comments, that not all users have posts and that some users don’t have an avatar. So the optional avatar field will be empty sometimes. For posts with no comments, you probably want to add a message like „Be the first to write a comment!“ and for the missing avatars, you probably want to display a placeholder image.
Why lots of data?
Quality is not the only requirement for sample data. Quantity is essential, as well. There’s a lot you simply can’t test without having lots and lots of entries.
Pagination and infinite scrolling
As soon as you have list views in your project, you probably need a way to either paginate them or implement infinite scrolling. While you can test the display of pagination elements and their behaviour with very little data, when it comes to infinite scrolling, there simply is no way around having a lot of data. Not only would a reload never be triggered on a normally sized browser window, you would never even be able to catch any performance issues with only a few entries. UX issues such as your footer never coming into the view as more and more entries are being loaded would never arise.
I can remember a case from a past project where we duplicated the same entries many times to test those things, and then missed a bug because our implementation was repeating the last entry of the previous block every time. Having the client catch errors like that after adding real content doesn’t help your relationship with them.
Find UX issues
As we’ve seen in the Lorem ipsum example above, diversity is important to catch issues. And having a lot of data can help with that. If you do it the wrong way, you get 1000 entries that are very similar and actually hide UI issues from you. Be aware of this and design your sample data in a way that resembles actual content. This includes not only different sized strings, but different amounts of sub entries and leaving out optional fields in some entries. Real content is normally very diverse, so your sample data should be as well.
Why simulate edge cases?
This is where most mocking solutions lack and why, for a long time, we hand-crafted our sample data manually on a project-to-project basis.
UX issues with long text
Design plays a vital role in professional projects and because of that, content elements often have very specific limits in size, restricting the amount of text that can be displayed inside them. The easiest way to solve this is by telling the client to curate content fitting those elements exactly. But you don’t always have that luxury. And even if you have, maybe those content elements have different sizes on mobile and desktop viewports, or the same content is displayed in different components all together, with varying sizes. Then you need to apply different solutions. One solution would be to truncate the content at specific max lengths, but this only works reliably if you use a monospaced font, making it useless in most cases. As you can easily see, having varying text lengths is essential to catch, solve and test these kinds of problems.
UX issues with unbreakable words
You would expect breaking words correctly is something browsers have figured out by now. Reality shows us that the this isn’t handled very elegantly, though. Everyone that has tried to solve this issue knows how difficult it can be. You definitely need long words in your test data to come up with good solutions that handle real content correctly.Here’s an example showcasing this issue nicely:

Exactly the same CSS rules were applied, but completely different behaviours in most browsers (Edge and IE act like Firefox in this case) are what follows. The error is easy enough to fix, but if your test data doesn’t contain long words, you may never know that you have to fix it till the client calls you after he added one of those words.
API errors and availability
A real API is much less predictable than a local JSON server which you control and nobody else accesses. But even if you already have a real API, chances are that the API is quite fast and stable during development, as it’s either deployed locally on your system or on some test server that doesn’t see much traffic. The real world is less predictable.
If traffic is high, your API could slow down a lot. Or on Black Friday, it might even be completely unreachable. While a good browser can help you test unreachable and slow APIs, having a mocked API that can simulate these situations is much more user friendly. Not only to test loading states—for example a spinner—but also for testing your error handling.
This is a FakeQL fragile API example response simulating an API that is temporary unavailable:
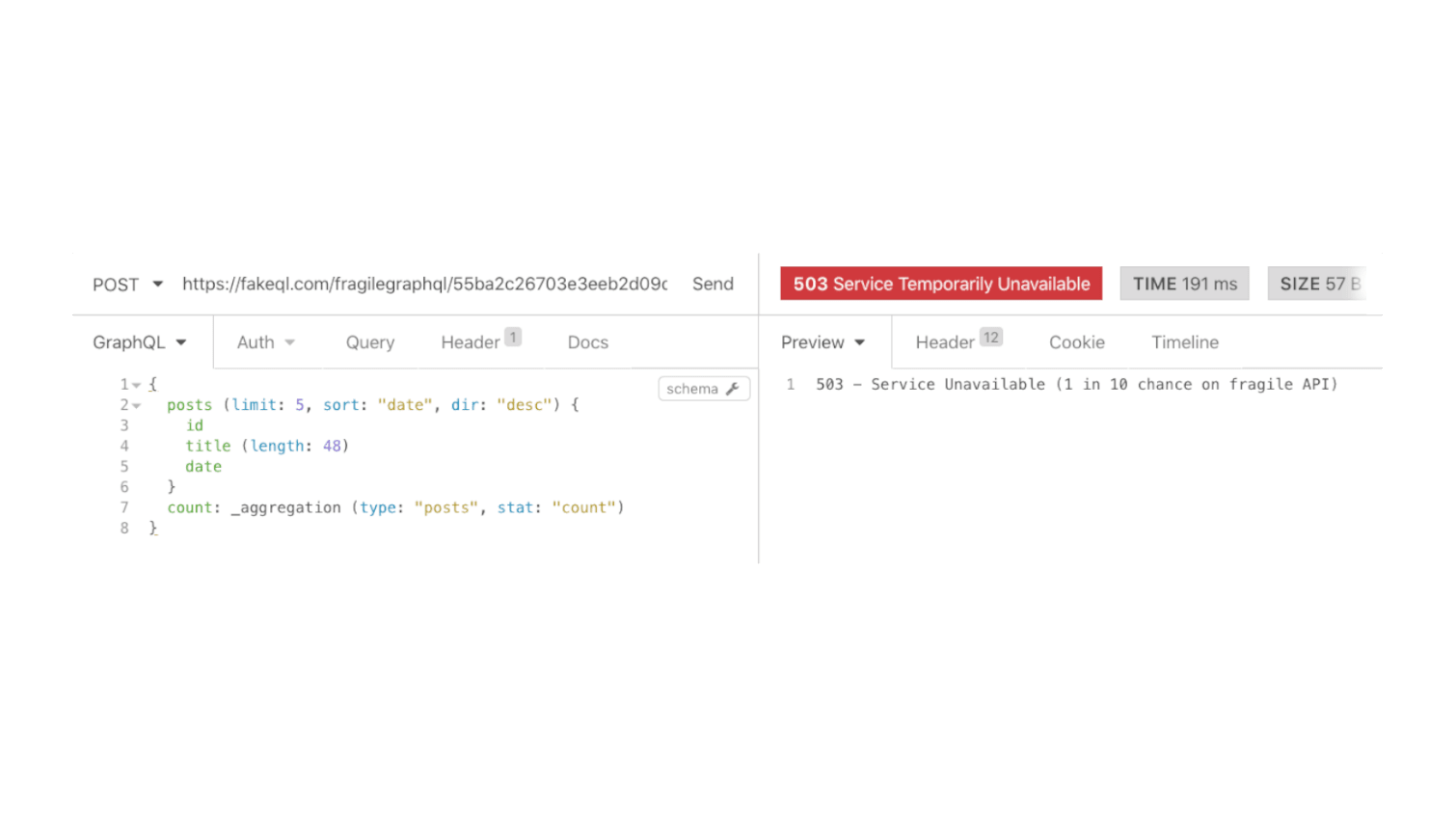
Why overwrite automatic data?
Many mocking tools use Faker.js, Chance.js or similar libraries to generate random sample data on each request. This is a bad idea for more than one reason.
Automation will never be perfect
You can automate data as long as you want, it will never be perfect. At least in the foreseeable future. Sometimes you need to be able to overwrite random data to catch very specific cases that came up while playing with real data. In any case, you want to be able to test those issues now and with every future update. Without the ability to overwrite generated data, this becomes an impossible task.
Some real client data can help
Let’s say the content team has started adding real content and found a few cases where that content isn’t displayed correctly. To replicate and fix those issues locally, it’s ideal to have that exact same content in your sample data or mocked API. However, if all your content is generated randomly on each request, overwriting that content is simply not possible. So catching those issues would be pure luck.
Why flexible data structures?
As you want to mock the real thing as closely as possible, the mocking service shouldn’t limit you in the kinds of data it can mock. Not all API services are built for easy consumption: pretty much every existing CMS or API service has it’s own idea of how to structure an API. Your mocking tool should be flexible enough to simulate every kind of structure.
Rigid backend services
One reason to mock a certain structure is because, for whatever reason, your backend doesn’t output a well-suited data structure. Worst case, you need to work with an old backend service nobody wants to touch anymore and your project team hasn’t enough resources to decouple that data structure from your frontend. Ideally, every API would be designed for consumption, but that’s just not the case in the real world.
Costs of developing custom APIs
Another big reason is the cost of developing a custom API that is better suited for consumption or the cost of decoupling and remapping an already existing API. In an ideal world we would only consume APIs made for consumption, but in the real world cost is a very important factor. And so good enough is often better than perfect.
The mocking service should not limit you
Even if the above two points are not applicable to your project, having a flexible mocking service is still preferable, as you never know what the future will bring. Flexibility saves you in this case from lock-in situations where you’re too much invested in the mocking service to want to switch to another one only because it can’t do that one thing for you.
Below is an example of recreating a Drupal-like data structure, using the special „_nest“ field from FakeQL and by using union types for paragraphs.
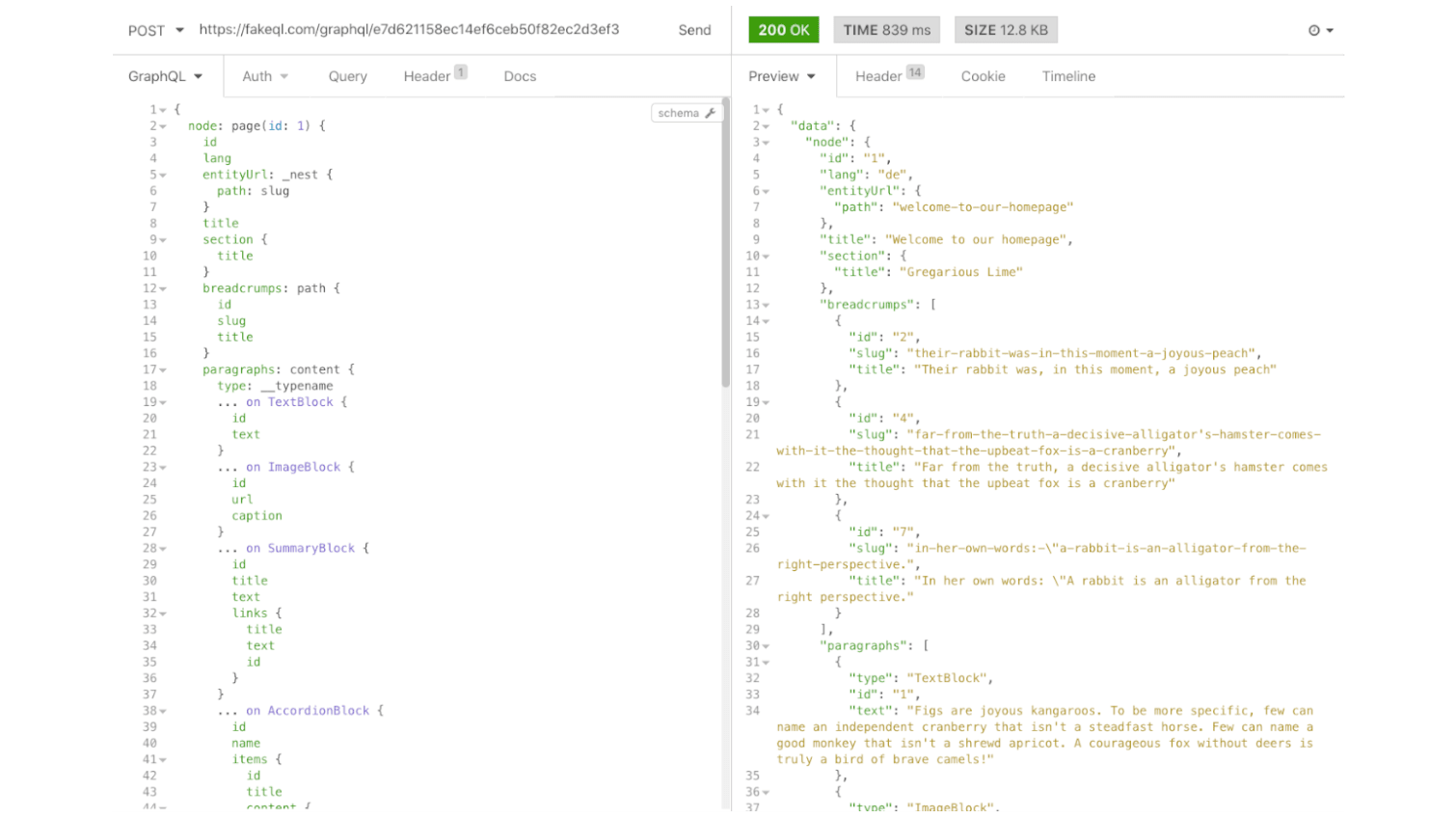
Supporting nesting and all the usual content relations, like one to one, one to many, many to many and union types, is the bare minimum for most big projects.
The query you send to the mocking service doesn’t need to be exactly the same as the one you later send to the backend. You can store those queries in separate files and some environment variable (dev or production) controls which ones to use. What’s essential is that the responses you get are the same, so that you don’t have to change anything in your business logic. That would be a lot of work and most likely prone to mistakes.
Why realistic behaviour?
An API is not only data—an API has a certain behavior. This can be anything from the correct order of execution of side effects to allowing mutations of data and those mutations then having the right behavior.
Find real world interaction issues early
A good example for this is an „optimistic UI“. Let’s say you have a list of products and a delete button next to each one. If you click the delete button, you probably want some immediate feedback. This can be anything from removing the entry to animating it out in some way. If the request fails, however, I want the product to reappear to make sure the user realises the action has failed. This can be handled in various ways, but without a mocked API and realistic behaviour and a way to simulate errors, things like this becomes really hard to test.
API delays
Sometimes errors can materialise because the order of arriving API responses is different from how you’ve sent them. This is known as a race condition in software development. These kinds of errors are impossible to find with local JSON servers, as responses have very similar and stable execution times for each request. A mocked API with random delays can help you find these issues early during development and not only in production where they are much harder to debug.
Why predictable?
A good API service uses randomness the first time it generates sample data. On all following request to the API, it serves from the same data again and again, so you can predict each output. Why is this important?
Unit testing
A mocked API is not only useful to build frontend prototypes, it also comes in really handy to unit test your API layer's side effects. But only if the data and behaviour are actually predictable for each request. The last thing you want in unit tests is random data. But this is exactly what happened with many of the services I’ve tested.
Integration testing
Even more important than in unit testing, a predictable API comes in very handy to do integration tests. To illustrate this, here’s a possible test case scenario that would be very impractical with unpredictable data:
Start test session (for example using Puppeteer).
Render a page with a list view.
Click on a specific item in that list and test if the detail view renders the correct data.
Edit the specific entry.
Go back to the list view and check if the entry has changed and is displaying the edited data (for example to test if your caching strategy works correctly).
Delete entry in list to test the correct optimistic UI behaviour.
End test session.
Visual regression testing
Consistent data is even more important for visual tests. Any small change in your sample data would completely throw off your pixel-based comparision tests, making it impossible to run any useful visual regression tests.
User testing
If your mocking service supports realistic CRUD operations with predictable outputs, you can even use it to test UX variations in user tests during the prototype phase. This simply wasn’t possible in the past and is very valuable to decide on implementations very early—before actually implementing the backend service or CMS configuration.
Why fast iterations?
It’s pretty much impossible to have the perfect solution for something from the beginning. That’s why most projects these days are developed agilely. Mocking an API can improve projects even more, simply because you can iterate on ideas even faster, as you don’t have to implement a real backend service for every change you want to try out.
Flexibility
Being able to iterate faster on your data structures and APIs gives you a lot of added flexibility. You can now tinker on your prototypes together with your client, in workshops for example. This is something that was completely unrealistic in the past, where backend services had to be implemented before you were able to test something on a real product.
Cost savings
Time is money. So fast iterations help you save costs. And even more importantly, they help you make better products.
Better products = Happier clients
Yes, paying less makes clients happy. But much more important to big clients is getting a better product. Being able to iterate faster on various features means being able to improve a product faster. The difference between having to implement something first and being able to mock it can be so big, that an improvement simply isn’t feasible without being able to mock an API.
Why effortless deploying?
Now of course all this added flexibility shouldn’t make a developer’s life worse. If implementing and maintaining a mocking service is too complicated, it doesn’t help anybody. If you can’t improve content on the fly during a client workshop, tinkering on the prototype becomes impossible.
Effortless content improvements
Improving specific content can be very important as we’ve seen above. However, in quite a few services I’ve tested before developing FakeQL, this was either not possible at all or very cumbersome.
Fast iterations on data structures
One of the key advantages of API mocking is that changing data structures is possible without having to re-implement the backend. Surprisingly, many mocking libraries and services make this hard to achieve.
Happy developers
I’m a developer and I can guarantee you that being happy on the job can have a direct impact on the quality of the product. We are just humans after all and not robots following instructions. Having great and enjoyable tooling helps a lot, so a mocking service should focus not only on having the most features, but being easy and fast to use at the same time.
Why privacy?
Some big projects can have privacy restrictions, making it impossible to use mocking services that don’t enforce privacy.
Client secrets
Having realistic sample data, while valuable for testing, can reveal a lot about the project you are building. Even if you trust the service you’re using to mock your API to never leak your data, very strict client contracts can prevent you from using it all together.
Sensitive data, national & EU laws
As soon as you add real content to your sample data, maybe even actual content of real users from a previous version of your product, you can run into situations where you come in conflict with national or EU data and privacy laws.
Don't expose attack vectors
Sample data exposes the schema of your backend and this can lead to hackers knowing enough about your product to have an easier time finding attack vectors.
FakeQL uses long random hashes to make it hard to find the endpoint of your mocked API, but as we know this isn’t always enough. We will, in a future update, additionally encrypt your sample data stored on FakeQL, so that only you can decrypt and read it with a private key.
API Mocking Solutions
We now have an idea of the requirements for a good mocking service. So let’s have a look at various available options, list their pros and cons and then have a look at our own solution.
GraphQL Editor
Pro
Nice visual schema editor
Can return empty results
Cons
Output is different on each call
No support for mutations
GraphQL only
Not optimized to test UI issues
Apollo Server
Pro
Simplifies the switch to the real backend immensely
Cons
Know-how on how to write GraphQL-based backends is mandatory
No concept to mock mutations
You need to host it yourself
GraphQL only
Not optimized to test UI issues
JSON Server & JSON GraphQL Server
Pros
Uses stable sample data
Support CRUD operations
Cons
You need to supply all data, no concept to extend data
You have to host the server yourself
IDs are not created automatically for new entries
Hasura JSON 2 GraphQL
Pros
Builds a real database
Great if you want to use Hasura
Cons
All data needs to be supplied by you
You need to host it yourself
Deploying can take a few minutes
Exposes no REST API
WireMock
Pro
Can be hosted via
Cons
Only a HTTP response stubber, no real API
Its interface is hard to understand
Mockable
Pro
Easy to use
Cons
No GraphQL support
Only a HTTP response stubber, no real API
Very limited feature set
Mocky
Pros
Easy to use
No account needed
Cons
No GraphQL support
Only a HTTP response stubber, no real API
Very limited feature set
Mockoon
Pro
No account or server required
Cons
Only a HTTP response stubber, no real API
Very limited feature set
Stoplight
Pros
Can be run locally on your computer
Supports Swagger
Cons
Account needed
Not a real API
No GraphQL support
Steep learning curve
Not optimized to test UI issues
Our Own Solution
As you can see, every option has more cons than pros – and not even one supports all features we think are essential. None of these options really satisfied our needs. While some of them are quite nice in what they do, all of them have missing features that are dealbreakers for our use case. None of them help us find UI or code issues in our projects. And none of them are well suited for Frontend First Development.
That’s how Blowson and later FakeQL were born.
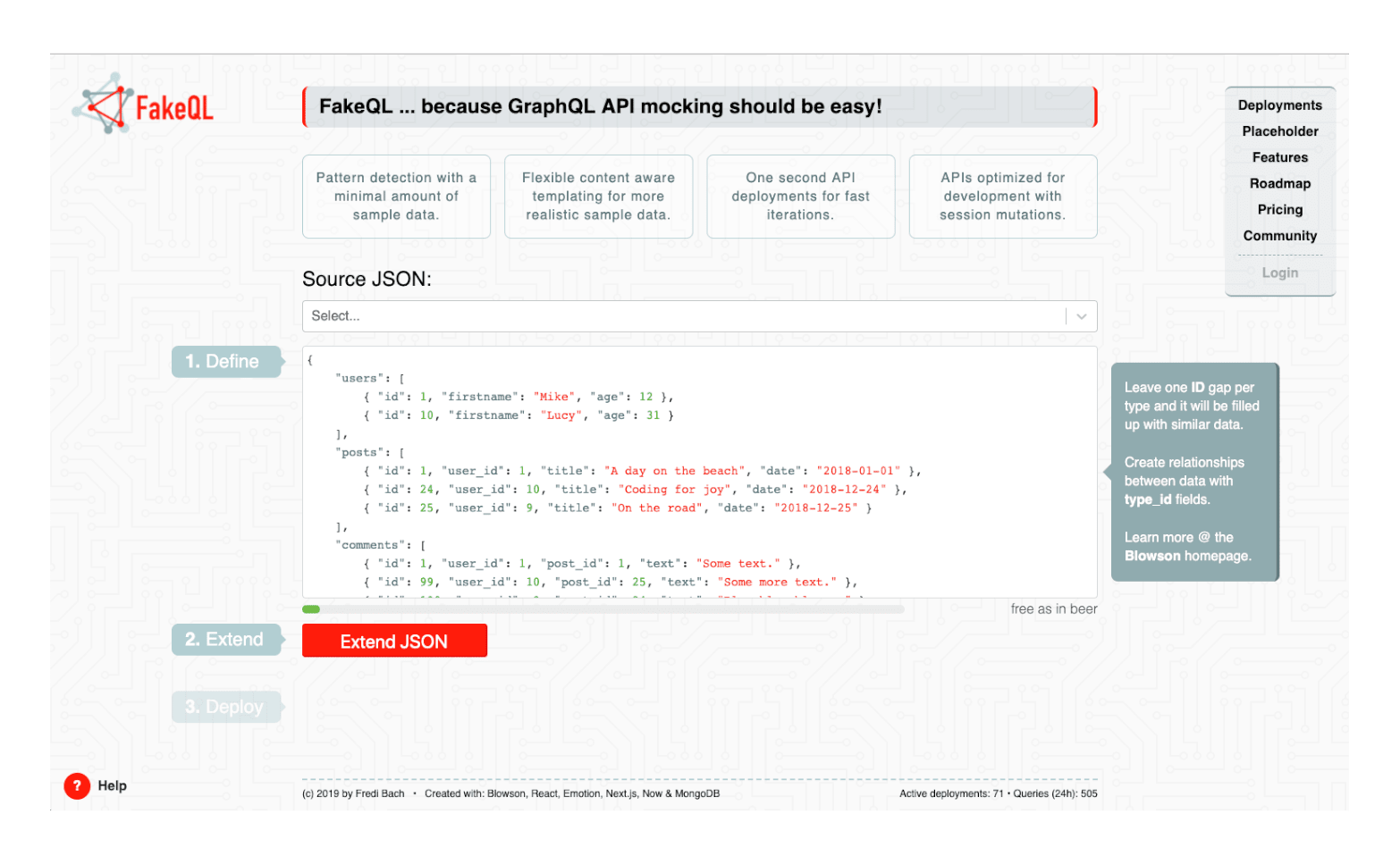
Let’s have a short overview of how they work and why they solve our use case:
First things first: A well-mocked API needs good sample data. That’s why we’ve developed Blowson, an open source library to extend a minimal JSON file with lots of similar data. What we mean by „minimal sample data?“ Here’s an example:

This is sample data for a simple ToDo app. There is a user type and a type for a user’s todos. If you take a closer look at the user type, you can see that we’ve already defined two users, one with an id of 1 and one with an id of 10. Blowson detects this range and adds new entries, 2 to 9, with the same fields as in those two entries. Additionally, Blowson knows what a firstname is, creating realistic new entries. Blowson has a whole host of useful detections to satisfy as many content needs as possible. Looking at the todo type, we see two entries and an id gap between 1 and 50. More interestingly, you have user_id fields on all entries. This is how you can define a one-to-many relationship between two types.
You can read the full documentation of Blowson here: Overview – Blowson.
So problem one: Solved. We have a good mechanism to create lots of realistic sample data. What we need now is a way to use that sample data to mock an API. That’s where FakeQL comes into play. It’s a web service that does three basic things:
Help you define minimal sample data like the above.
Extend that sample data with one click by using Blowson – no need to install anything.
Deploy the extended sample data as a GraphQL and REST API.
The deployed API is a real API with all the features you need to develop an application, but optimized for development and testing. For example, all mutations will be reset after five minutes of inactivity. This makes sure that every test session has the exact same behaviour, returning the exact same data for the exact same sequence of queries. Furthermore, you can simulate a server under load with the fragile version of the API. And because deployments can be done in a few seconds, it’s easy to iterate on your sample data.
Development of FakeQL started in early 2019, so it’s quite new and may still be subject to change. But we’re already successfully using it in real client projects. It helps us build our frontend and move faster than ever before.
Summary
This is how FakeQL can help you create better products, ship them faster, avoid stumbling over bugs in production and ultimately make clients happier:
Create lots of realistic sample data with minimal effort.
Deploy a real GraphQL and REST API optimized for development.
On-the-fly deployments during development via Webpack plugin.
Start implementing frontend prototypes before the backend is ready.
Iterate faster with clients on specific features.
Find UI, UX and business logic issues before deploying a finished product.
And there's even more to come! Until now Blowson contains no machine learning. This will change at some point in the future. For example, we want to detect languages and then generate fake sentences in those languages. And finally, we have some very clear ideas on how to refactor Blowson, adding a plugin environment. Meaning everyone can write their own detection and template logic.
Bonus
FakeQL is an ideal tool for Frontend First Development:
Firstly, define sample data for your project.
Then use the mocked API to develop the whole frontend.
If you’re happy with the implementation, copy the type definitions from the API and start writing the GraphQL resolvers.
This is how I’m building all my small private projects now and I couldn’t be happier with this workflow!
Another nice use case is to teach GraphQL. Being able to simply setup a GraphQL endpoint in seconds and then let your colleagues play around with it is a great way to help them learn it.


Contact for your Digital Solution
Book an appointmentAre you keen to talk about your next project? We will be happy exchange ideas with you.





Contact for your Digital Solution with Unic
Book an appointmentAre you keen too discuss your digital tasks with us? We would be happy to exchange ideas with you.

