


Eine gesamte Schnittstelle realistisch zu mocken ist sehr wertvoll, vor allem in agilen Projekten, wo eng mit dem Kunden zusammengearbeitet wird, oder in Headless-Projekten, wo REST oder GraphQL-APIs die einzige Kommunikationsschicht darstellen. Gutes Mocking kann Testing einfacher machen und UI- und UX-Probleme früh aufdecken. Da wir mit den bestehenden Lösungen nicht zufrieden waren, schrieben wir kurzerhand unseren eigenen Service – FakeQL.
In diesem Artikel werde ich erklären, was gutes Mocking ausmacht, warum es wichtig ist und wie Kundenprojekte von diesem neuen Tooling profitieren können. Das Ziel ist es, bessere Produkte zu kreieren, Kunden zufriedener zu machen und Kosten zu senken.
Mocking von Daten – die Grundlage
Daten und APIs realistisch zu mocken ist eine überraschend schwierige Aufgabe. Man sollte meinen, dass für so einen integralen und wertvollen Teil jedes Projekts Dutzende von Tools und Web-Services herumschwirren; dass es Hunderte von Artikeln gibt und gefestigte Best-Practices. Die Realität ist allerdings leider ziemlich düster. Auch wenn es viele HTTP-Stubbing-Services gibt, um spezifische Anfragen zu testen, ist echtes API-Mocking eine Seltenheit.
API-Mocking bei Unic
Wir bei Unic setzen uns schon lange mit API-Mocking, also dem Testen von Schnittstellen mit quasi-realen Daten und Endpunkten, auseinander. In letzter Zeit, vor allem, da wir immer mehr Headless-Projekte machen, entwickelte sich unser internes API-Mocking rapide weiter – zu etwas wirklich Nützlichem.
Warum eine API simulieren?
Es gibt viele Gründe, warum man eine API mocken sollte. Schauen wir uns die Wichtigsten gleich zuerst an!
Das Backend ist noch nicht bereit
Der wohl häufigste Grund, warum Schnittstellen gemockt werden, ist, dass sie schlichtweg noch nicht vorhanden sind. Dies kann oft passieren, da Backend- und Frontend-Teams oftmals zwar parallel arbeiten, aber Frontend-Dinge fertig sein müssen, bevor das Backend etwas liefern kann. In einer idealen Welt würde das niemals passieren. Aber echte Projekte werden immer in der echten Welt entwickelt, deswegen ist so etwas die Norm und nicht die Ausnahme.
Der Inhalt ist noch nicht bereit
Auch wenn das Backend existiert: Ohne Inhalte, idealerweise viel davon, ist es von keinem grossen Nutzen für uns. Wenn sich das Projekt um einen Relaunch handelt, so kann man wahrscheinlich alte Daten importieren und dieses Problem einfach lösen. Meistens muss allerdings händisch nachgeholfen werden. Das ist zeitintensiv, da für viele Features wie etwa Pagination zwei Einträge nicht ausreichen. Und vom Kunden erwarten, dass er diesen Part übernimmt, können wir nicht. Abgesehen davon ist es keine überaus befriedigende Beschäftigung.
Schnellere Iterationen
Falls das Backend da ist und es Inhalte gibt, so macht es trotzdem Sinn, weiterhin APIs zu mocken. Die Möglichkeit, schneller neue Versionen während der Entwicklung rauszubringen, ist ein sehr guter Grund dafür. Backend-Implementationen ändern kann sehr teuer und zeitaufwendig sein. Aber da Projekte monatelang andauern, ist es nur natürlich, dass Change Requests ins Haus flattern, denn sie sind Teil eines jeden guten Produkts.
Man kann ein Projekt so gut planen, wie nur möglich – man wird niemals die Optimallösung gleich von Beginn an haben, das ist einfach nicht realistisch. Es ist also wichtig, komplexe Änderungen am Backend so lange wie möglich zu verhindern. Mit einer gemockten Schnittstelle kann ein Produkt einfacher, schneller und billiger weiterentwickelt werden. Ist die vorgegaukelte Schnittstelle bereit, kann man direkt mit dem Kunden zusammen in Echtzeit Optimierungen vornehmen. Kunden benötigen oft schon früh einen Prototypen, um zu verstehen, was die Pros und Kontras ihrer Vorschläge sind. Diese Art von Workflow ist immens wertvoll, um Kostenexplosionen zu verhindern.
Um das Problem bezüglich Timing weiter aufzuzeigen, hilft folgende Illustration:

Wie zu erkennen ist, überlappen die Arbeit des Frontends und des Backends meist während eines Projekts. Der Inhalt, oftmals vom Kunden kommend, gesellt sich erst sehr spät dazu. Das macht auch Sinn so, denn das Meiste muss bereits fertig sein, bevor der Kunde mit dem Einpflegen des Contents beginnt.
Im Frontend-Stream, normalerweise nach dem initialen Setup, braucht man wahrscheinlich Zugang zu den APIs, noch bevor diese überhaupt fertig sind. Beide beschriebenen Probleme sind mit roten Abschnitten im obigen Bild dargestellt. Eine Schnittstelle so früh wie möglich mocken – dieser Workflow wird von uns Frontend-First-Development genannt –, kann beide verhindern.
Die Utopie des Mockens
Wir haben also festgestellt, dass Mocken wirklich nützlich ist. Aber was muss eine perfekte Lösung beinhalten? Lasst uns mal alle möglichen Limitierungen vergessen und eine optimale Lösung herträumen. Steht diese, werden wir sie mit bereits existierenden Lösungen vergleichen.
Nicht unterscheidbar von der echten Schnittstelle
Das ist die wichtigste Anforderung. Die gemockte API soll so nah wie möglich an der effektiven Implementation sein. Wenn man das Problem ein bisschen genauer anschaut, merkt man allerdings, dass unsere Lösung eigentlich sogar besser sein sollte als die schlussendliche. Warum?
Edge Cases hervorheben
Öfter, als gedacht, verstecken echter Inhalt und echte Implementationen mögliche UX-Probleme. Gutes API-Mocking sollte diese hervorheben. Durch variable Längen des Inhalts und Einsatz von sehr langen Wörtern, beispielsweise. Weiterhin sollte es möglich sein, Netzwerk-Überlastungen zu simulieren.
Zusammengefasst heisst das im Grunde genommen, dass ein Mocking-Service besser sein soll als das finale Produkt. Nicht nur bezüglich der Änderungsfreundlichkeit, sondern auch bezüglich der Fähigkeit, mögliche Probleme frühzeitig zu erkennen.
Unser Weg bei Unic
Bei Unic haben wir schon sehr früh erkannt, dass Mocking unabdingbar ist. Hier ein kleiner Überblick über unsere Vergangenheit in diesem Bereich:
2012: Statische JSON-Dateien
2014: Durch JavaScript erweiterte JSON-Dateien
2016: JSON-Server via localhost
2018: Durch Blowson erweiterte Daten als JSON via localhost
2019: Gemockte API-Services via FakeQL
Wir sind mit lokalen JSON-Dateien in unseren Frontend-Prototypen gestartet. Schnell haben wir aber gemerkt, dass das für die meisten Projekte nicht gut genug ist. Also wechselten wir auf JSON-ähnliche JavaScript-Dateien, die wir dann verwendeten, um unsere Module und Seiten statisch auszugeben. Auch das reichte nicht lange, und wir wechselten auf lokal gehostete Mini-Server.

Die Entwicklung von Blowson und FakeQL
2018 habe ich gemerkt, dass mit dem Wechsel zu Headless CMS und immer wie komplexeren Projekten, wie progressiven Web-App und Single-Page-Applications, unser Tooling nicht mehr ausreichte. Also startete ich die Arbeit an Blowson und später an FakeQL. Blowson ist eine Open-Source-Bibliothek, die intelligent JSON-Daten erweitert; FakeQL ist ein Service, um diese dann einfach und als GraphQL- oder Rest-API zu deployen.
Funktionen einer grossartigen Lösung
Einen guten Mocking-Service zu schreiben ist, wie ich herausfinden musste, nicht so einfach, wie ich ursprünglich gedacht habe. Nachfolgend das Feature-Set, welches sich herauskristallisiert hat:
Viele realistische Inhalte einfach generieren
Automatisch generierte Daten überschreiben
Einfaches Deployment (für glückliche Entwickler)
Realistisches Verhalten
Schnelle Iterationen ermöglichen, um herumbasteln zu fördern
Vorhersehbar sein, sodass automatisierte Tests möglich werden
Flexible Datenstrukturen simulieren
UI-, UX- und Netzwerk-Edge-Cases simulieren
Privatsphärerichtlinien von Kunden respektieren
Warum realistische Daten?
Realistische Daten sind ein absolutes Must. Aber «realistische Daten» sind komplexer, als man zunächst vermuten mag. Die Erfahrungen, die wir über die Jahre gesammelt haben, haben uns einiges an wertvollem Wissen gegeben. Wir wissen, was funktioniert und was nicht, was UX-Probleme aufdeckt und was sie versteckt.
Lorem ipsum ist ein Problem
Viele Mocking-Tools fallen hier bereits durch. Während «Lorem Ipsum» zwar als Platzhaltertext konzipiert wurde, macht es seinen Job im Kontext des Webdesigns nicht sehr erfolgreich. Der Fehler, den viele Entwickler machen, ist, dieselben Teile von Lorem ipsum immer wieder zu kopieren und einzufügen.
Skripts, die automatisch Lorem-ipsum-Texte generieren, verhindern dieses Problem indem sie willkürliche Teile des Texts ausspucken. Das viel grössere Problem ist allerdings, dass Lorem ipsum nicht dazu geeignet ist, Edge-Cases zu simulieren. Allen voran im Deutschen oder im Französischen, wo lange Wörter keine Seltenheit sind. Weiterhin endet jeder Satz mit einem Punkt, beinhaltet keine Zitate und abgetrennte Begriffe. Fehler, die beim Umbrechen von Wörtern auftreten, sind also komplett unvorhersagbar.
Um dieses Beispiel zu verdeutlichen, sieht man unten eine naive Anwendung von Lorem ipsum. Neben normalem Content werden die versteckten Probleme gleich klar. Wie auf den Bildern zu sehen ist: Hätten wir das Layout mit Floats gebaut, hätten wir schon eine fehlerhafte Darstellung.



Überraschungen mit realistischem Content vermeiden
Nur realistischer Inhalt kann mögliche Fehleranfälligkeiten mit Styles und Layouts aufdecken. Vorangehensweisen wie Lorem ipsum oder Bibliotheken wie Faker.js vereinfachen einem das Leben vorerst, aber können, wie oben gezeigt, künftige Probleme kaschieren. Lange Zeit hat dies bedeutet, dass richtiger Inhalt von Hand geschrieben werden musste oder, falls möglich, von der alten Website übernommen wurde. Auch wenn Copy-&-Paste heute mit Tools wie Blowson eigentlich nicht mehr nötig ist, so macht es dennoch Sinn, einige Einträge selbst anzulegen, bevor man seinen Code in die produktive Umgebung schickt.
Leere Felder korrekt behandeln
Was viele vergessen, wenn sie Testdaten erstellen, sind leere Einträge und fakultative Felder. Ein echtes Datenschema hat oftmals optionale Felder oder erlaubt leere Arrays. Wenn man einfache Testdaten von Hand schreibt, ist es sehr einfach, diese Bedingungen zu vergessen. Das kann allerdings zu verschiedenen Problemen wie ungestylten Nachrichten oder Layout-Fehlern führen, da ein Teil der Seite nicht da ist.
Sagen wir, wir bauen eine Blog-API mit Benutzern, Einträgen und Kommentaren nach. Es ist zu erwarten, dass nicht alle Einträge Kommentare haben und dass nicht jeder Benutzer einen Avatar hochlädt. Das optionale Avatar-Feld wird manchmal also einfach leer sein. Falls ein Eintrag keine Kommentare hat, sollte eine Nachricht à la «Sei der Erste, der etwas schreibt!» eingeblendet werden. Für die fehlenden Profilbilder wäre es wohl am Besten, ein Platzhalterbild anzuzeigen.
Warum viele Daten?
Qualität ist nicht die einzige Bedingung für Testdaten. Quantität ist ebenso essenziell. Es gibt viele Aspekte, die schlichtweg nicht getestet werden können, wenn man nur wenig Content zur Verfügung hat.
Pagination und Endlos-Scrolling
Sobald man Listenansichten in seinem Projekt hat, wird man damit konfrontiert, wie man mit vielen Daten umgehen will. Die populärsten Arten sind eine simple Paginierung und sogenanntes Endlos-Scrollen. Man kann zwar mit wenigen Daten ein «Zur nächsten Seite gehen» simulieren, aber wenns um unendliches Scrollen geht, so gibt es keinen anderen Weg. Denn ein Neuladen würde nie ausgelöst und man wäre nicht in der Lage, Leistungsprobleme zu erkennen. UX-Probleme, etwa dass man den Footer der Seite gegebenenfalls niemals sehen würde, blieben ebenfalls unentdeckt.
UX-Fehler finden
Wie wir bereits beim Lorem-ipsum-Beispiel oben gesehen haben, ist es wichtig, UX-Fehler abzufangen. Viele Inhalte zu haben, hilft dabei. Wenn man es allerdings falsch angeht, so erstellt man 1000 Einträge, die alle ähnlich sind und Fehler auf der Benutzeroberfläche vor einem verstecken. Man sollte sich dem immer bewusst sein und Testdaten möglichst realitätsnah schreiben. Das bedeutet nicht, einfach nur verschieden lange Strings zu erstellen, sondern auch verschiedene Mengen an Untereinträgen und von Zeit zu Zeit das Weglassen von optionalen Feldern zu berücksichtigen. Echter Inhalt kann sehr divers sein, also sollten es Testdaten auch sein.
Warum Edge-Cases simulieren?
Hier haben die meisten Mocking-Tools ihre liebe Mühe, was auch der Grund war, warum wir lange Zeit unsere Testdaten manuell eingeben mussten.
Probleme mit langem Text
Das Design spielt eine wichtige Rolle in professionellen Projekten, und deswegen haben Inhaltselemente oftmals spezifische Limitierungen bezüglich Höhe und Breite. Natürlich könnte man dem Kunden sagen, er solle doch bitte nur Inhalte erfassen, die diesen Limitierungen gerecht werden. Aber dies ist natürlich nicht zu empfehlen. Und da diese Elemente auf verschiedenen Geräten verschiedene Mengen an Text aufnehmen können, ist dies so oder so nicht empfehlenswert. Man könnte probieren, den Text nach einer gewissen Anzahl Zeichen abzutrennen, aber das würde auch nur bei nicht-proportionalen Schriftarten klappen. Mit langen und kurzen Texten zu testen, ist daher von grösster Bedeutung.
Probleme mit ungebrochenen Wörtern
Man würde erwarten, dass das Umbrechen von Wörtern etwas ist, was Browser inzwischen im Griff haben. Leider zeigt ein kleiner Test, dass dem nicht so ist. Jeder, der schon einmal probiert hat, dieses Problem selbst zu lösen, weiss, wie schwierig es sein kann. Um auf solche Fälle reagieren zu können, ist es unabdingbar, mit langen Wörtern herumzuspielen.

Genau dieselben CSS-Regeln wurden angewendet, aber viele Browser (Edge und IE verhalten sich gleich wie Firefox) rendern andere Resultate. Der Fehler ist zwar einfach zu beheben, aber wenn er gar nie erst auftritt, so ist es gut möglich, dass er vergessen wird.
Schnittstellenfehler und Ausfälle
Eine echte API ist viel weniger berechenbar als ein lokaler JSON-Server, auf welchen niemand anders zugreift. Aber selbst wenn man mit einer wirklichen Schnittstelle testet, so ist die Wahrscheinlichkeit, dass sie während der Entwicklung schneller und stabiler reagiert als in der echten Welt, ziemlich hoch.
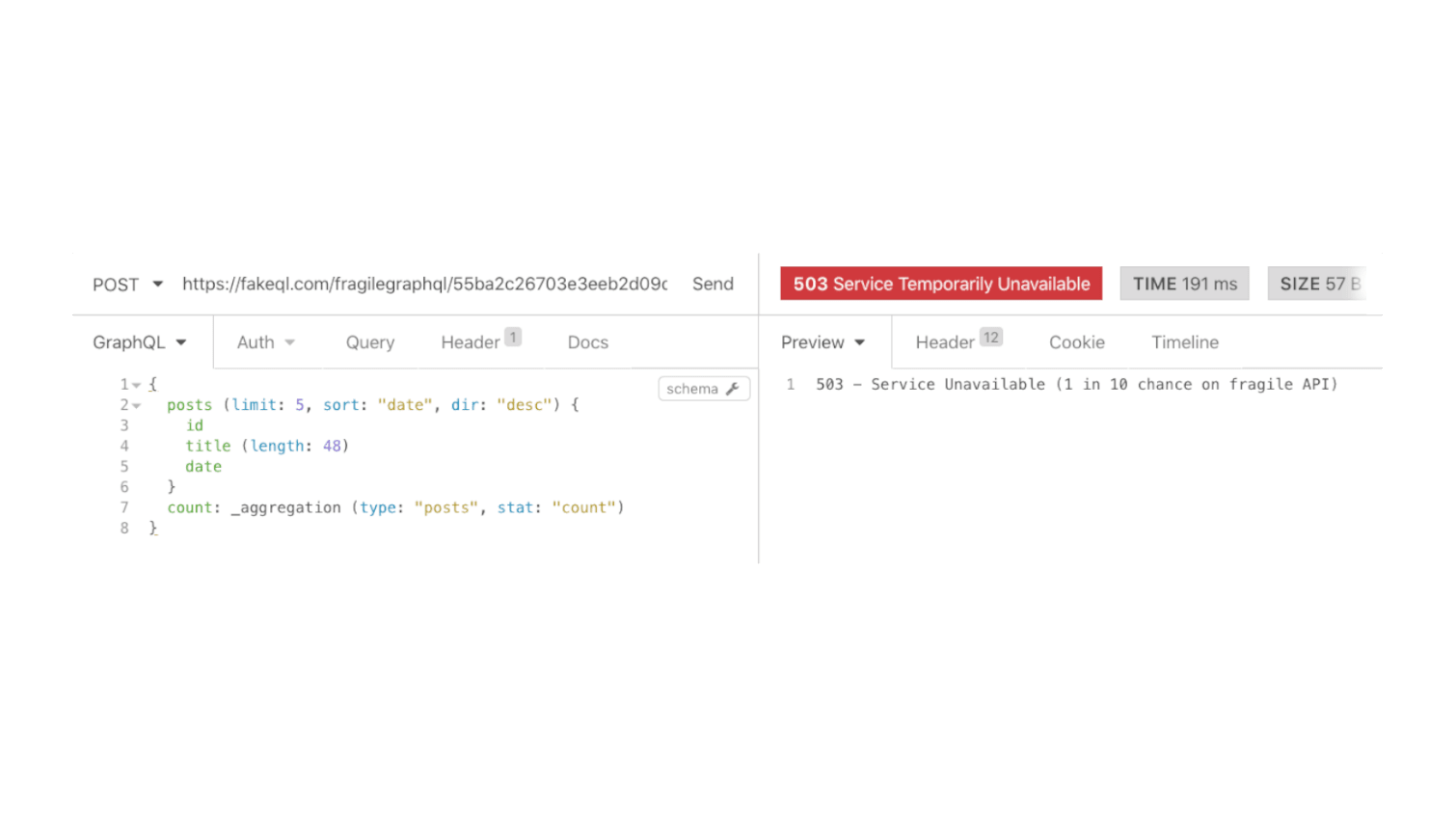
Wenn der Netzwerkverkehr hoch ist kann das eine Schnittstelle immens bremsen. An Black Fridays kann eine Schnittstelle auch unter der Last zusammenbrechen. Ein guter Mocking-Service kann solche Szenarien nachahmen. So kann man sich darauf vorbereiten und etwa einen Spinner anzeigen, dauert das Holen der Daten länger als gewohnt. Ausserdem ist es auch hilfreich fürs Abfangen von Fehlern, an die man sonst gar nie denkt.
Eine fragile GraphQL-Schnittstelle via FakeQL kann etwa so aussehen:
Warum automatisch Daten überschreiben?
Viele Mocking-Tools verwenden Faker.js, Chance.js oder ähnliche Bibliotheken, um willkürliche Daten bei jeder Anfrage zu generieren. Das ist allerdings aus mehreren Gründen eine schlechte Idee.
Automatisierung wird niemals perfekt sein
Man kann Daten-Generierung automatisieren so viel wie man will – sie wird nie perfekt sein. Zumindest nicht in der vorhersehbaren Zukunft. Manchmal muss man in der Lage sein, einen gewissen (willkürlichen) Datensatz gezielt zu manipulieren, um spezifische Fälle zu überprüfen. Ohne die Möglichkeit, diese schnell und einfach abzuändern, wird es allerdings unmöglich, auf alles vorbereitet zu sein.
Ein paar echte Inhalte können helfen
Das Team hat damit begonnen, echten Inhalt einzupflegen und ist dabei auf die Situation gestossen, dass irgendetwas nicht korrekt dargestellt wird. Um das lokal zu replizieren und beheben ist es ideal, den genau gleichen Content zu haben, wie der Kunde. Wird der Inhalt jedoch bei jeder Anfrage neu generiert, ist das nicht möglich. Solche Fehler zu finden wäre dann pures Glück.
Warum flexible Datenstrukturen?
Da man so realitätsnah wie möglich mocken möchte, sollte einem der Service nicht vorschreiben, wie die Datenstruktur auszusehen hat. Nicht alle Services sind für die einfache Konsumierung konzipiert: so ziemlich jedes existierende CMS hat seine eigene Idee, wie eine API aussehen sollte. Das Mocking-Tool sollte so flexibel sein, dass es alle möglichen Strukturen ausgeben kann.
Starre Backends
Ein Grund eine spezifische Struktur zu mocken kann auch sein, dass das Backend aus irgendeinem Grund eine unpassende Struktur ausgibt. Im schlimmsten Falle muss mit einem alten Service gearbeitet werden, der von niemandem mehr betreut wird. Idealerweise wäre eine API dafür designt, einfach zu konsumieren zu sein, aber das ist manchmal einfach nicht der Fall.
Kosten der Entwicklung einer massgeschneiderten API
Ein anderer Grund sind Kosten. Massgeschneiderte Schnittstellen sind optimal, aber sehr teuer. Also ist gut genug oftmals besser als optimal.
Der Mocking-Service sollte keine Beschränkungen aufzwingen
Auch wenn die beiden oberen Punkte nicht auf ein Projekt zutreffen – flexible Mocking-Tools sind trotzdem zu präferieren, da man niemals weiss, was die Zukunft bringt. Flexibilität bewahrt davor, in folgende Situation zu geraten: Man hat sich zu sehr auf einen Mocking-Service fokussiert, um auf einen anderen zu wechseln, nur da ersterer die eine Funktionalität nicht hat, auf welche man angewiesen ist.
Hier ist ein Beispiel, das eine Drupal-änhliche Antwort zurückliefert, mit dem speziellen _nest-Feld von FakeQL:
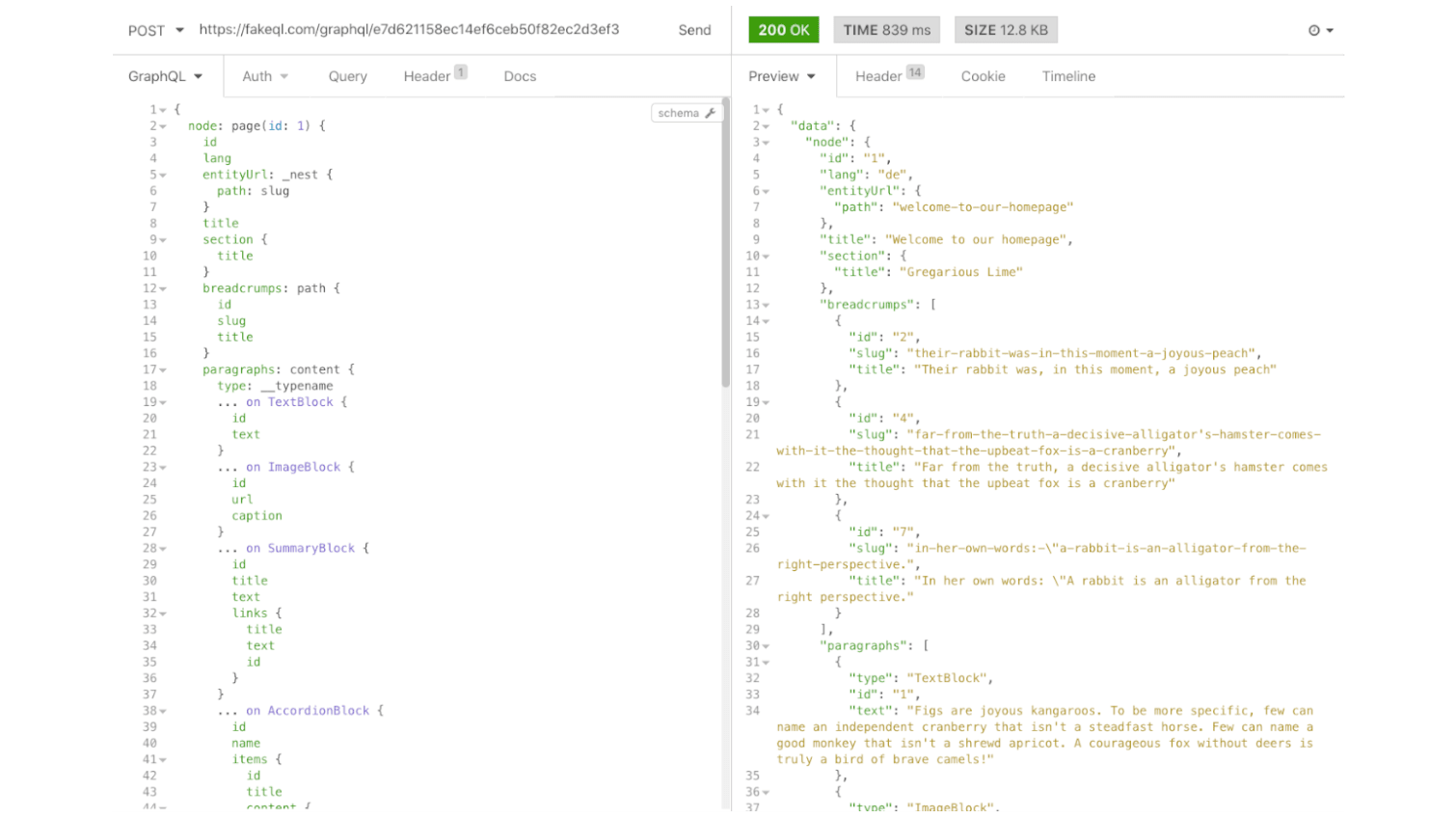
Nesting und alle anderen gewöhnlichen Datenbeziehungen, wie eins-zu-eins, eins-zu-mehrere, mehrere-zu-mehrere und Union Types, sind das Minimum für die meisten grösseren Projekte.
Die Anfrage, die zum Service geschickt wird, muss nicht unbedingt dieselbe sein, wie die, die schlussendlich ans Backend geschickt wird. Die Queries können in separaten Dateien gespeichert werden. Über Umgebungsvariablen (meist development und production) wird dann kontrolliert, aus welcher Datei die Abfragen stammen. Essenziell ist, dass die Antworten dieselben sind, sodass nichts in der Applikationslogik geändert werden muss. Das wäre viel Arbeit und sehr wahrscheinlich fehleranfällig.
Warum realistisches Verhalten?
Eine Schnittstelle ist nicht nur Inhalt. Eine Schnittstelle hat ein bestimmtes Verhalten. Das kann alles sein, von der korrekten Ausführungsreihenfolge bis hin zum Erlauben von Datenmutationen.
Probleme mit «Real World Interactions» frühzeitig erkennen
Ein gutes Beispiel hierfür ist «Optimistic UI». Sagen wir, wir haben eine Liste von Produkten und einen «Löschen»-Button neben jedem Produkt. Wenn der Button gedrückt wird, erwartet man sofort irgendeine Art von Rückmeldung. Sei es, dass das Produkt gleich verschwindet oder dass eine Animation stattfindet. Wenn die Anfrage allerdings missglückt, sollte das Produkt wieder auftauchen, um dem Benutzer zu signalisieren, dass etwas schiefgelaufen ist. Das kann über diverse Wege gehandhabt werden, aber ohne eine gemockte API mit realistischem Verhalten, die Fehler simulieren kann, wird es sehr schwierig, solche Fälle zu testen.
Verzögerungen
Manchmal können Fehler auch auftreten, wenn die Reihenfolge der ankommenden Server-Antworten anders ist als diejenige der Anfragen. Solche Fälle nennt man «Race Conditions». Sie sind unmöglich mit lokalen JSON-Servern zu testen, da diese sehr stabile Ausführungszeiten für jede Anfrage haben. Eine gemockte Schnittstelle mit willkürlichen Verzögerungen kann dabei helfen, solche Sachverhalte früh während der Entwicklung abzufangen und nicht erst, wenn das Projekt bereits auf der Produktionsumgebung ist.
Warum vorhersehbar?
Ein guter Schnittstellen-Service bedient sich beim ersten Generieren der Testdaten an Willkürlichkeit. Alle folgenden Requests werden immer von derselben Quellen gezogen, sodass die Ausgabe vorhersehbar ist. Aber warum ist das wichtig?
Unit Testing
Eine gemockte Schnittstelle ist nicht nur zum Erstellen von Frontend-Prototypen sehr hilfreich, sondern auch zum Unit Testing. Jedoch nur, wenn ihr Verhalten und die zurückgegebenen Daten konsistent sind. Das Letzte, was man für Unit Tests will, sind inkonsistente Daten. Aber das war genau das, was passierte, als ich mit vielen Services gearbeitet habe.
Integrationstests
Sogar noch wichtiger als bei Unit Tests: Vorhersehbare Daten sind ein Muss für Integrationstests. Um aufzuzeigen, warum: Hier ein mögliches Testszenario, welches mit unvorhersehbaren Daten sicherlich nicht durchgehen würde:
Die Session starten (zum Beispiel mit Puppeteer).
Eine Seite mit einer Listen-Ansicht ausgeben.
Klick auf ein spezifisches Listenelement und schauen, ob die Ansicht die korrekten Daten rendert.
Das ausgewählte Element editieren.
Zurück zur Listen-Ansicht gehen und schauen, ob das Element erfolgreich geändert wurde (um etwa eine Caching-Strategie zu testen).
Listenelement löschen, um die Optimistic-UI-Verhaltensweise zu testen.
Die Test-Sitzung beenden.
Visuelles Regressionstesting
Konsistente Daten sind nochmals einen Deut wichtiger für visuelle Tests. Jede noch so kleine Änderung der Testdaten würde pixelbasierte Prüfungen sofort rot aufleuchten lassen. So wird visuelles Regressionstesting komplett nutzlos.
Nutzertests
Wenn der Mocking-Service realistische CRUD-Operationen (Create; Read; Update; Delete) mit vorhersehbaren Antworten bieten kann, so ermöglicht dies das Testing von UX-Variationen in Nutzertests in der Prototypen-Phase. Das war in Vergangenheit schlichtweg unmöglich, ist aber eigentlich etwas sehr Wertvolles. So können Entscheidungen gefällt werden, bevor das Backend auch nur einen Finger rühren muss.
Warum schnellere Iterationen?
Es ist so ziemlich unmöglich, die perfekte Lösung von Anfang an zu haben. Und das ist auch der Grund, warum die meisten Projekte heutzutage agil entwickelt werden. Eine API gescheit zu mocken, kann Projekt-Workflows um einiges vereinfachen, denn so können Ideen schneller angeschaut und Module schneller optimiert werden, ohne dass irgendein Backend-Service für jeden kleinen Change (um)geschrieben werden muss.
Flexibilität
Die Möglichkeit, effizienter an Datenstrukturen und Schnittstellen zu arbeiten, gibt einem sehr viel Flexibilität. Man kann nun sogar zusammen mit dem Kunden an Prototypen herumspielen – in Workshops, beispielsweise. Auch das wäre früher niemals möglich gewesen, wo Endpunkte vorhanden sein mussten, bevor man irgendetwas am effektiven Produkt testen konnte.
Kosteneinsparungen
Zeit ist Geld. Das heisst, dass uns schnelle Iterationen Geld einsparen. Und noch wichtiger: Sie helfen, bessere Produkte zu machen.
Bessere Produkte = zufriedenere Kunden
Ja, weniger zu zahlen, macht Kunden glücklich. Aber für Grosskunden ist es integraler, ein gutes Produkt zu kriegen. Schnellere Iterationen bedeuten auch, dass man schneller an diversen Funktionalitäten arbeiten kann und folglich Fehler schneller ausgemerzt werden können. Der Unterschied dazwischen, etwas effektiv zu implementieren und etwas einfach zu mocken, kann gigantisch sein.
Warum müheloses Deployen?
Diese ganze neue Flexibilität sollte das Leben des Entwicklers nicht komplizierter machen. Wenn die Implementierung und die Instandhaltung eines Mocking-Services zu schwierig sind, hilft er niemandem. Kann man nicht mit einem Kunden in Echtzeit an Features arbeiten, so wird auch wichtiges Ausprobieren am Prototypen unmöglich.
Mühelose Inhaltsverbesserungen
Spezifischen Content zu verbessern, kann situationsbedingt sehr wichtig sein, wie wir oben gesehen haben. Allerdings war das in vielen Services, die ich getestet habe, bevor ich mit FakeQL angefangen hatte, entweder sehr mühsam oder gar nicht erst möglich.
Schnelle Iterationen auch an Datenstrukturen
Wie wir nun hundert Mal gehört haben, ist eines der Schlüsselargumente von API-Mocking die Effizienz und die Geschwindigkeit, die es mitbringt; dass Änderungen an Datenstrukturen vorgenommen werden können, ohne dass das Backend etwas neu implementieren muss. Überraschenderweise ist das aber auch mithilfe von vielen Mocking-Services nicht einfach hinzukriegen.
Glückliche Entwickler:innen
Ich selbst bin Entwickler und ich kann garantieren, dass die Zufriedenheit beim Job einen direkten Einfluss auf die Qualität meines Codes hat. Auch wir sind nur Menschen und keine Roboter, die Instruktionen folgen. Gutes und angenehmes Tooling hilft sehr, den Happyness-Pegel hoch zu halten. Ein Mocking-Service sollte also nicht nur viele Funktionalitäten mitbringen, sondern auch einfach zu bedienen sein.
Datenschutz?
Manche Grossprojekte haben Restriktionen, was den Datenschutz angeht. Somit fallen alle Dienste weg, die es mit dem Schutz von Unternehmensdaten nicht wirklich genau nehmen.
Kundengeheimnisse
Realistische Beispieldaten, wenn auch integral fürs Testing, können ungewollt vieles über ein jeweiliges Projekt verraten. Auch wenn man dem Mocking-Service komplett vertraut, dass die Daten sicher aufgehoben sind und nicht «leaken», so können restriktivere Kunden die Nutzung von externen Produkten aus diesem Grund untersagen.
Sensible Daten, nationale sowie EU-Gesetze
Sobald echter Content in den Mix kommt, vielleicht sogar Inhalte von echten Benutzern von einer früheren Version des Produkts, kann man in Situationen geraten, in denen man sich mit nationalen oder internationalen Daten- bzw. Privatsphäre-Gesetzen konfrontiert sieht.
Attackenvektoren kaschieren
Beispieldaten können das Schema eines Backends offenlegen. Das kann einigen Hackern schon ausreichen, um bedrohliche Attacken zu starten.
FakeQL generiert lange, willkürliche Hashes, wodurch es ungemein schwierig wird, Endpunkte einer Schnittstelle zu finden. Aber wie wir wissen, reicht das nicht immer aus. In kommenden Versionen werden wir zusätzlich alle Dummy-Daten verschlüsseln, sodass nur du sie mithilfe eines privaten Schlüssels lesen kannst.
API-Mocking-Lösungen auf dem Markt
Inzwischen haben wir eine gute Idee davon, was einen guten Mocking-Service ausmacht. Nun können wir uns die Produkte anschauen, die schon auf dem Markt sind, und sie mit unseren Anforderungen abgleichen.
GraphQL Editor
Pro
Schöner, visueller Schemen-Editor
Kann leere Resultate zurückgeben
Kontra
Jede Antwort ist unterschiedlich
Keine Unterstützung für Mutationen
Nur GraphQL
Nicht für UI-Probleme geeignet
Apollo Server
Pro
Vereinfacht den Umstieg auf eine richtige API immens
Kontra
Extensives GraphQL-Know-How ist zwingend
Keine Unterstützung für Mutationen
Man muss den Server selber hosten
Nur GraphQL
Nicht für UI-Probleme geeignet
JSON Server & JSON GraphQL Server
Pro
Stabile Dummy-Daten
Unterstützt alle CRUD-Funktionen
Kontra
Alle Daten müssen selbst geschrieben werden
Man muss den Server selber hosten
IDs müssen für jeden Datensatz selber definiert werden
Hasura JSON 2 GraphQL
Pro
Generiert eine echte Datenbank
Grossartig, wenn Hasura eingesetzt werden soll
Kontra
Alle Daten müssen selbst geschrieben werden
Man muss den Server selber hosten
Deployments können mehrere Minuten dauern
Keine REST-Unterstützung
WireMock
Pro
Kann via MockLab gehostet werden
Kontra
Nur ein HTTP-Stubber, keine richtige API
Schwierig zu verstehende Benutzeroberfläche
Mockable
Pro
Einfach zu benutzen
Kontra
Keine GraphQL-Unterstützung
Nur ein HTTP-Stubber, keine richtige API
Sehr limitierte Funktionalität
Mocky
Pro
Einfach zu benutzen
Kein Konto nötig
Kontra
Keine GraphQL-Unterstützung
Nur ein HTTP-Stubber, keine richtige API
Sehr limitierte Funktionalität
Mockoon
Pro
Kein Konto oder Server nötig
Kontra
Nur ein HTTP-Stubber, keine richtige API
Sehr limitierte Funktionalität
Stoplight
Pro
Kann lokal auf dem Computer ausgeführt werden
Kann mit Swagger integriert werden
Kontra
Konto nötig
Keine richtige API
Keine GraphQL-Unterstützung
Steile Lernkurve
Nicht für UI-Probleme geeignet
Unsere eigene Lösung
Wie wir sehen, hat jede verfügbare Option mehr Kontras als Pros. Und nicht eine einzige unterstützt alle Funktionalitäten, die wir als essenziell ansehen. Keine Lösung hat uns zufriedengestellt. Auch wenn einige davon ziemlich nett sind, so ist das limitierte Feature-Set für uns ein absoluter Deal-Breaker. Keine Lösung unterstützt beim Finden von UI- oder Code-Problemen. Und keine ist gut kombinierbar mit unserer Frontend-First-Philosophie.
So wurden Blowson und später FakeQL geboren.
Im Folgenden eine Übersicht davon, wie sie funktionieren und wie sie für unseren Use-Case Sinn machen:
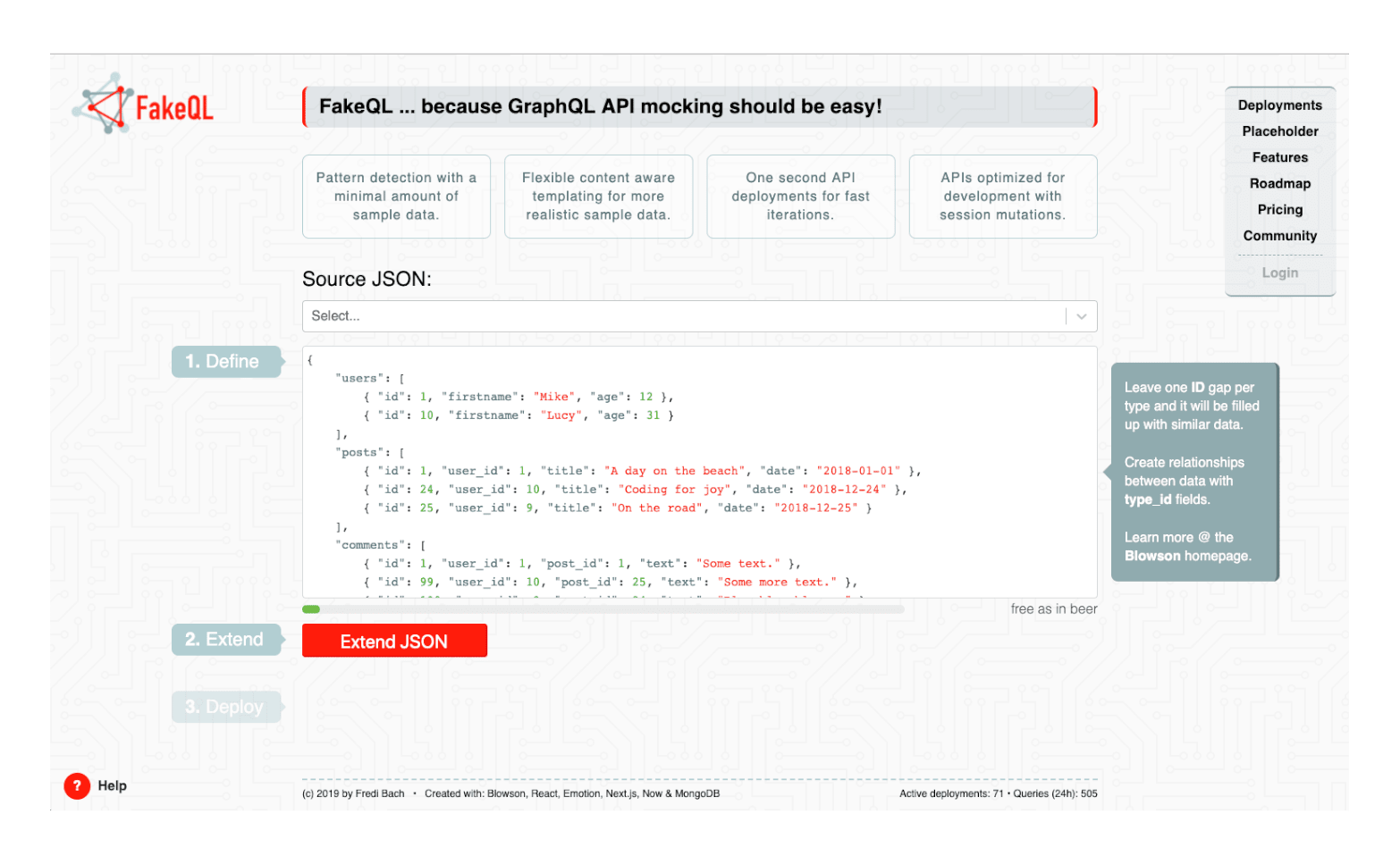
Das Wichtigste als Erstes: Eine gute gemockte Schnittstelle braucht gute Dummy-Daten. Dafür ist Blowson da – eine Open-Source-Bibliothek, welche es möglich macht, ein kleines JSON mit vielen ähnlichen Daten zu erweitern. Was mit «kleines JSON» gemeint ist kann hier gesehen werden:

Hier sind ein paar Beispieldaten für eine einfache To-Do-App. Es gibt einen Benutzertypen und einen Typ für die To-Dos eines Benutzers. Schaut man sich den Benutzertypen an, so sieht man, dass wir schon zwei Benutzer definiert haben: einen mit einer ID von 1 und einen mit der ID von 10. Blowson detektiert diese Lücke und fügt neue Einträge mit den IDs 2 bis 9 hinzu. Zusätzlich weiss Blowson, was ein «firstname» ist und generiert auch hier realistische neue Einträge. Blowson kann diverse Felder erkennen und befriedigt so viele Content-Anforderungen wie möglich. Schauen wir uns den To-Do-Typen an, so sehen wir zwei Einträge und einen Bereich von 1 bis 50. Hier sehen wir auch «user_id»-Felder. Blowson kann über diese Felder Eins-zu-viele-Beziehungen schaffen, falls gewünscht. Die komplette Dokumentation kann hier gelesen werden: Overview – Blowson.
Problem eins: Gelöst! Wir haben einen guten Mechanismus, viele realistische Beispieldaten zu generieren. Was wir jetzt noch benötigen ist einen Service, der uns diese Daten einfach konsumierbar zur Verfügung stellt. Hier kommt FakeQL ins Spiel. Denn FakeQL ist ein Web-Service, der vor allem drei Sachen macht:
Eine minimale Anzahl an Dummy-Daten kann eingespiesen werden.
Die Dummy-Daten werden beliebig automatisch erweitert.
Die erweiterten Daten werden als GraphQL- und REST-API deployt.
Die deployte Schnittstelle ist eine echte Schnittstelle, mit allen Funktionen, die man braucht, um eine Applikation zu entwickeln. Nichtsdestotrotz ist sie darauf optimiert, den Aufwand für Entwicklung und Testing so gering wie möglich zu halten. Beispielsweise werden alle Mutationen nach fünf Minuten Inaktivität zurückgesetzt. So kann sichergestellt werden, dass jede Test-Sitzung dasselbe Verhalten aufweist und dieselben Daten für die dieselben Anfragen zurückgibt. Weiterhin kann ein Server simuliert werden, der unter hoher Belastung steht. Da ein Deployment weniger als eine Sekunde in Anspruch nimmt, können die Beispieldaten sehr flexibel und on-the-fly angepasst werden.
Die Entwicklung an FakeQL hat Anfang 2019 begonnen. Der Service ist also noch relativ jung und wird eventuell einige grössere Veränderungen durchmachen. Wir setzen sie allerdings schon erfolgreich in echten Kundenprojekten ein. FakeQL hilft uns, unser Frontend aufzubauen und schneller zu sein, als jemals zuvor.
Zusammenfassung
So kann FakeQL helfen, bessere Produkte zu kreieren, sie schneller auszuliefern, nicht nach Go-Live über Bugs zu stolpern und, wenn wir ehrlich sind, Kunden glücklicher zu machen:
Kreieren von vielen realistischen Beispieldaten.
Deployen einer richtigen und optimierten GraphQL- und REST-Schnittstelle.
Flexibles Deployen während der Entwicklung über ein Webpack-Plugin.
Entwicklungsbeginn fürs Frontend, bevor das Backend steht.
Schnelleres Iterieren – zusammen mit dem Kunden.
Finden von Fehlern in den Bereichen UI, UX und Applikationslogik, bevor das Produkt irgendwo veröffentlicht wird.
Bis anhin beinhaltet Blowson keine Machine-Learning-Algorithmen – das wird sich aber ändern. Wäre es nicht schön, wenn Blowson automatisch Sprachen erkennen könnte und dann korrekte Sätze in der jeweiligen Sprache generieren würde? Um das Ganze abzurunden, haben wir schon eine klare Idee, wie wir Blowson umschreiben können, sodass ein Plugin-Ökosystem möglich wird. Jeder wird die Möglichkeit haben, seine eigene Erkennungs- und Template-Logik zu schreiben.
Bonus
FakeQL ist ein ideales Tool für Frontend-First-Development:
Ein minimales Set an Dummy-Daten definieren;
die Daten erweitern und deployen;
falls man zufrieden mit der Implementation ist, die GraphQL-Resolver schreiben.
Genau so mache ich seit einiger Zeit alle meine eigenen kleinen Projekte nebenbei, und ich könnte nicht glücklicher mit dem Workflow sein!
Ein anderer schöner Use Case für FakeQL ist das Unterrichten von GraphQL. Eine Schnittstelle innert wenigen Minuten aufzusetzen und dann seine Kollegen damit experimentieren lassen ist ein grossartiger Weg, ihnen zu helfen, die Technologie kennenzulernen.




Wir sind da für Sie!
Termin buchenSie möchten Ihr nächstes Projekt mit uns besprechen? Gerne tauschen wir uns mit Ihnen aus.





Kontakt für Ihre digitale Lösung mit Unic
Termin buchenSie möchten Ihre digitalen Aufgaben mit uns besprechen? Gerne tauschen wir uns mit Ihnen aus.

